Revamping a Five-Year Old Node.js Project
Introduction
This article introduces the complete migration process, including the architecture choice, migration steps, service assurance, and the challenges encountered during the migration.
Background
Our team has been using React Native and React.js for a long time. The Rncache service not only supports the download of javascript offline packages but also provides API services for C-end customers in the app.
The service supports many applications, including over 590 React Native applications, more than 290 instances of the React.js mini-program offline package, and 18 instances of other applications.
The service handles nearly 3,000 QPS daily, with peak QPS over 10,000.
If the service fails, it would significantly affect the user experience.
However, after five years of development, the original project accumulated many technical debts:
-
High priority services (C-end services) depend on low priority services SDP(Static Deploy Platform) and some middlewares are not supported anymore.
-
The Rncache service retrieves data from SDP and shares Redis with it, which could lead to potential Redis eviction issues. The SDP service, created five years ago as an internal B-end service, depends on over 10 downstream services. The architecture violates design principles and is really easy to crash down. A single problem in any of these underlying services could lead to the C-end service crash down.
Target
To address the above issues, we have the following goals:
- Decouple from B-end service SDP, migrate the logic of the C-end part in SDP to a new Graff project.
- Use a separate Database and Redis.
- Enhance the monitoring and logging of the Rncache service.
Architecture Change
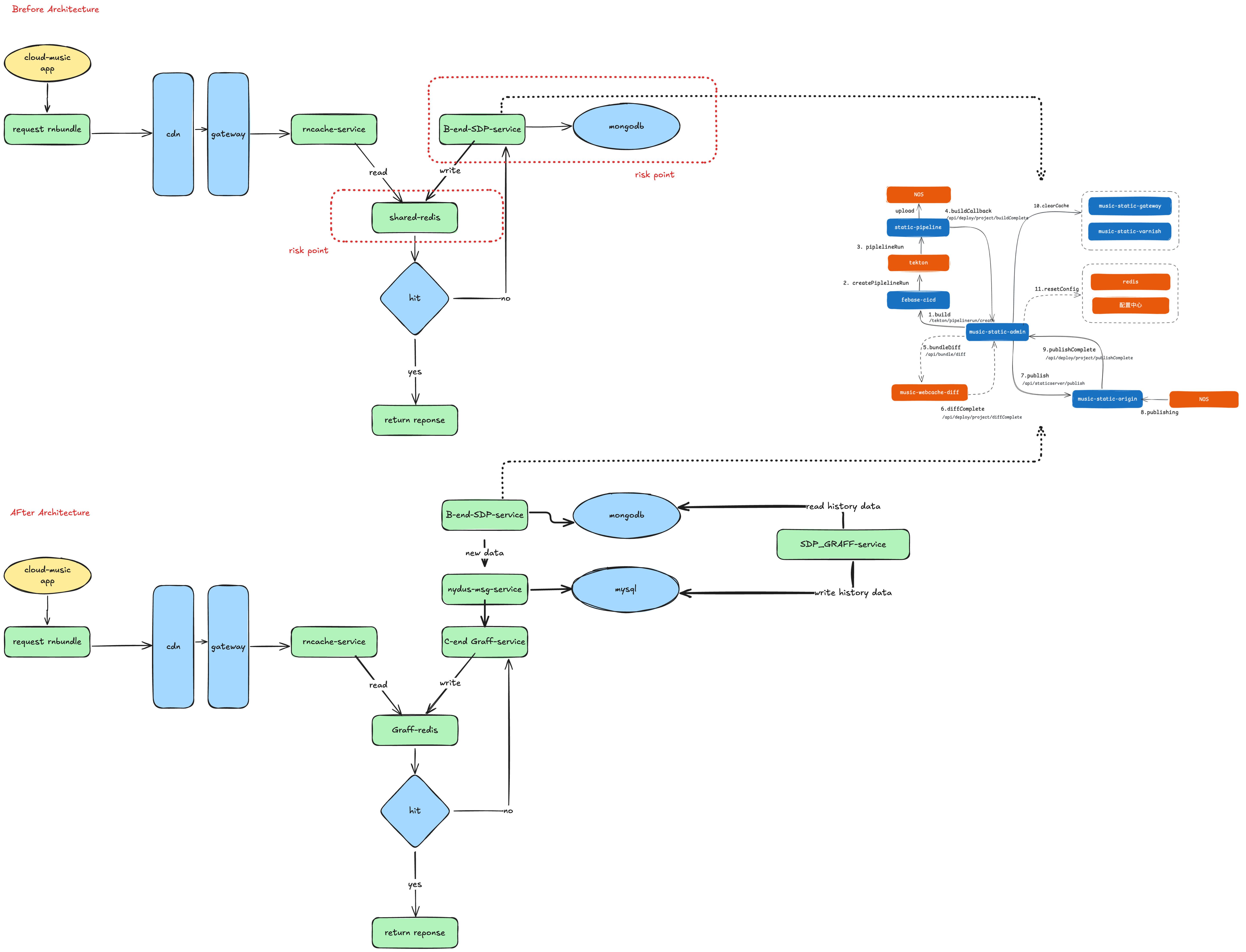
Before Migration:
When the client requests the Rncache service, if the Redis cache is hit, the cached data from Redis is returned directly. If the cache is not hit, it will fallback to SDP Service.There are two risks in the original architecture which already caused several incidents in production:
Shared Redis: The Cache Service does not have it own independent redis; it shares the same redis with SDP service. When Reids memory is full, the Redis memory will be evicted indiscriminately,leading to a chain reaction.
Fallback to SDP: When the Redis cache service is not hit, there might be tremendous requests fallback to SDP service (accroding the daily QPS). The SDP service was initially designed for internal use and cannot handle such high pressure from C-end. The SDP servcie depends on over 10 downstream services which is really easily break. A single problem in any of hese underlying services could lead to the C-end service crash down.
After Migration:
In comparison, an independent C-end Graff-service is created with its own Redis and Mysql and placed between Rncache Service and SDP Service.
Independent Redis and Database: In the new architecture, when the client requests the data, it will first check the Graff-Redis, which is exclusively for the Rncache Service.
New C-end Graff-Service: If the Redis cache is not hit, it will fallback to Graff Service rather than directly relaying to SDP service.
Data Synchronization: To ensure a smooth migration and no impact on client user experience,it is need to guarantee the synchronization of historical and incremental data, as well as the complete and accuracy of the data.
So, our tasks are:
- Services Development.
- Data Synchronization.
- Redis Update.
- Services Guarantee.
Services Development
Tech Stack Choice
The old tech stacks are KoaJS + MongoDB + MoogooseJS + Javascript, which are outdated and lacking monitoring.
The new tech stacks are MugJS(a mvc framework based on Eggjs) + MySQL + Sequelize + Typescript, which are more modern and support better monitoring, testing and scalability. We choose these frameworks after thinking about the infrastructure of our company and the experience of the team.
Database Mapping
The old database is MongoDB, while the new database is MySQL. The data structures and schemas are different, so we need to transform the data from MongoDB to MySQL, especially nested document type in MongoDB. Do we just keep that a string field in MySQL or create a new table when encounter a nested document type?
After careful consideration, our idea is- make migration as simple as possible.
So we first keep it a string field. If there is some performance issue, we can then extract it into a new table.
There are some other fields need to be transformed:
-
The
_idin MongoDB corresponds tomongoidstring field in Sequelize. we can use mongoid to track every old record. -
The
timestampsin MongoDB is the “ISODATE format, which converted toyyyy-mm-dd hh:mm:ss. -
Nested document typein MongoDB is converted to a string field in MySQL,specifically thelongtexttype. -
Types that are difficult to handle in MongoDB, such as
arrays, should be converted tostringsand processed at the Sequelize ORM layer. -
Other fields should be referenced based on the model structure in SDP and converted to Sequelize syntax.
-
You can use AI to help you transform the data schema, write some prompts based on LangGPT framework.
Endpoints Develeopment
There are a lot of business logic and endpoints in SDP, so we need to extract them and create new APIs in the Graff service. There are total 16 endpoints need to rewrite. We can leverage the ChatGPT to transform the APIs and optimize the source code manually. Below are some tough points:
Populate Syntax Problem
When querying the project information in SDP, a foreign key odpAppGroupIds is used to perform a join query and retrieve the AppGroup information. However, after migration to MySQL, our company DDB(database department) does not allow foreign key association which may lead to performance issues. The total number of AppGroup is almost 25, so we can handle it by creating a adapter function in Graff service.
The original populate syntax in MongoDB is:
const rnProject = yield Project.findOne(
{
// ...
odpAppGroupIds: {
$in: odpAppGroupIds,
},
},
"id odpAppGroupIds envs"
).populate("odpAppGroupIds");
The new syntax in MySQL is:
public async findAllWithAppGroup(options?: FindOptions | undefined): Promise<any> {
const [ projects, appGroupMap ] = await Promise.all([
this.findAll(options), this.appGroupService.getAppGroupMap(),
]);
// compatible with populate
return projects.map(project => {
const appGroupIds = project.odpAppGroupIds || [];
const appGroups = appGroupIds.map(appGroupId => appGroupMap[appGroupId])
.filter(appGroupItem => appGroupItem);
return {
...project.get(),
odpAppGroupIds: appGroups,
};
});
}
History Data Correlation.
When comparing the response of the same endpoints returned by SDP and Graff, we find the Graff returns more records than SDP.
In MongoDB, you can easily change the field type even there is already existing data.
For example, the field rnBasicVersion initially is the type int and then changed to string. But in MySQL, we cannot change the field type and keep it as string. There are 6 rnBasicVersion is int 0 in production environment and 5000 in test environment in SDP. It is really hard to find out the problem when you have so many records just like finding a needle in a haystack. Finally, we can filter to response to return the correct data.
(baseVersionsRange[index] || [])
.filter((baseVersion) => {
return typeof baseVersion._id.rnBasicVersion === "string";
})
Data Synchronization
Historical Data Synchronization
For existing data, we created a SDP-Graff project to handle the problem.
This service connects both MongoDB and MySQL database simultaneously, and use the same table names and field names. It will read data from MongoDB according the Database Mapping and write them into MySQL. Except that, there are still places that need to notice.
-
Handling Large Data Volumes: The
BundleInfotable has 400000 records in test enviroment and 200000 records in production and every record has a large size. We need to using skip and limit to transfer 100 records each time to avoid Mysql memory problem Or you will encounter the error likeGot a packet bigger than 'max_allowed_packet' bytes. Just transfer a small batch every time. -
Creating Indexes: Pull out the original indexes in MongoDB and migrated them in MySQL.
-
Comparsion Database records: We created a website to compare the total count of each table in MongoDB and MySQL, as well as the latest reocrd. If the two are equal, we can ensure the synchronization is correct.
-
Handling Missing Fields: There are so many tables and fields in MongoDB that you cannot find them all at once. There are always some missing fields in MySQL. So, we created a page to alter the table in MySQL and transfer related data.
Incremental Data Synchronization
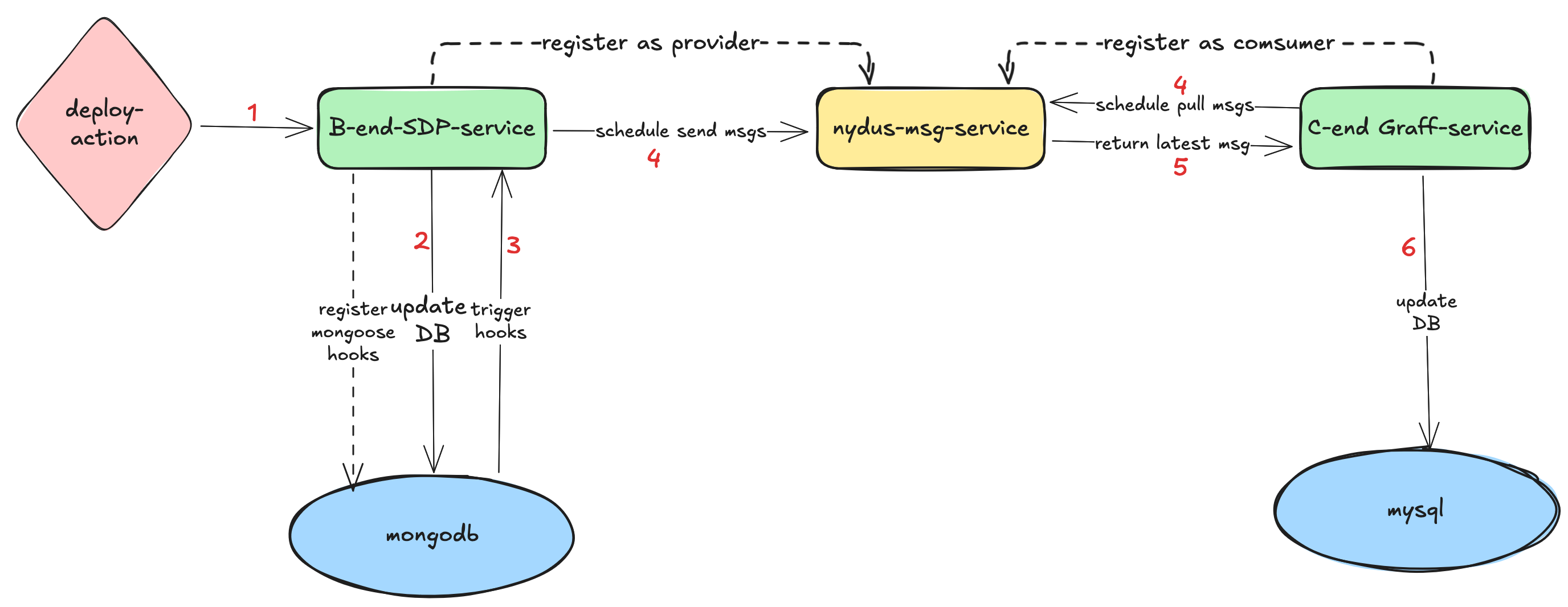
Compare to handling historical data, handling incremental data is more complex. The process is illustrated in the diagram above. When an deploy action is trigged, it nesscary to sync the data from SDP service to Graff service. There are three key steps: detecting change, notifycing changes, and processing changes.
Change Detection
When a deploy action is trigger, the SDP service need to detect changes in MongoDB. There are several ways to listen for changes in the database, such as
DB call-site hook,DB change events,Mongoose hooks。
DB call-site hook
This approach is very straight, which adding the message-sending source code at all places in SDP project where database operations are performed.
The disadavatnage of it is that it requires significant changes to the codebase and easily missing some places as well as increasing the code redundancy.
DB change events
MongoDB support change events, which means we can subscribe to database change events. When changes happen, it will notify the SDP and we can broadcast the message to Nydus.
The advantage is its simplicity and low code redundancy, but the disadvantage is it is hard to handle in multi-process scenarios.
In production environment, we often deploy multiple instances or pods of a servcie. Each instance or pod has many processes. So if each process subscribes to the database change events, messages may be sent multiple times or the order may be incorrect. For example, if the database notifies two ordered events, evt1 and evt2, which processed by different process, the order of evt1 and evt2 cannot be guaranteed.
Except the order problem, there are other issues:
-
if a process crashes, it will hold the global lock all the time if we use global lock silution to handle the order problem.
-
There is no retry mechanism,and the message will be lost.
So we need to split the change detection into two steps:
-
Detecting changes and storing them.
-
Use a scheduled task to send the events sequentially based on the order in which they occurred.
However, even though there is a clusterTime field in MongoDB points out the time of operation happened,it is not supported in our current version 3.6.
Mongoose Hooks
The approach uses the hooks feature of Mongoose ORM library, which is combined the two above approaches. Its advantages are:
- It is relatively easy to understand, with low code redundancy.
- It allows for multi-process usage.
- Messages can be retried if sending fails.
So, this is our final choice.
Change Notification
-
According Load Balance policy, when writing data to MongoDB, there is only one mongoose hook instace to handle, so we don’t need care about the duplicate problem.
-
Create a
NydusProviderLogtable in MongoDB to store all the change events. Setup a scheduled task to check the oldest unsuccsufull or not sent message and send them sequentially. If any message sending fails, it will be retried until successful and alter the monitor system.
The format of change event send by SDP service is:
interface MsgData {
data:{
bundleinfos?: [],
projects?: [],
appgroups?: [],
},
type:"model_update|model_insert|model_update_ignore|model_delete"
}
Change Processing
-
We also create a
NydusConsumerLogtable in Mysql to record monogoid, nydus id and updatedMongoTime such things. -
Using a scheduled task to pull the data every 60 seconds from Nydus,process the change and update the related Mysql table.
Redis Update
The Redis is used to improve the performance of Rncache Service and there are two points need to notice:
-
Invalid and update Redis cache must be in the same service. We do these in Graff service. If you invalidate in Graff and update in Rncache, it will lead to performace issue and crash all the services. Because Redis is empty at some time if you invalidate and update in different service. when that happens, the Rncache have to fallback to downstream service. According the QPS, the downstream service will undertake a huge pressure.
-
The Redis Key Concatenation Rule must be consistent. We spend a lot of time to find out the key problem as they don’t follow the same rule. A typical Redis key is
MUSIC_RNCACHE_RES_V2_ios_moyirn_api-qa-wine.moyis.163.com_moyi_modifyprofile. There are several parts in the key:
MUSIC: AppGroupID, 25 kinds.RNCACHE: Project type name, 3 kinds.RES: Resource type name,almost 4 kinds.V2: Resource version, 3 kinds.ios: Platform, 2 kind.moyirn: Platform name,2 kinds.api-qa-wine.moyis.163.com: Env name,9 kinds.moyi: App name, almost 900 kinds (590+290+18).modifyprofile: Id, tremendous.
There are so many keys and records in Redis, we need to make sure they apply the same rule at the first place.
Migration Guarantee
After finishing the development of underying services, data synchronization and Redis update, we need to ensure the migration is correct. There are three ways to assurance that: Endpoints Comparsion, Endpoints Switch, Gray Release.
Endpoints Comparsion
There are 16 API need to migrated, we create a automated comparision service running after every publish to compare the response of SDP and Graff . If the two responses are exactly the same, it means the migration is correct. If there is some difference, we will investigate and fix the problem. This is first step to guarantee.
Endpoint Switch
For each C-end cache service, a SDPGraffSwitch item is created in our NCM configuration center. This item has three values, each with a different meaning:
- 0: Full fallback to SDP, directly request the SDP API, returning data from SDP.
- 1: Compare SDP and Graff. If they match, take Graff’s data; if not, take SDP’s data.
- 2: Full fallback to Graff, directly request the Graff API, returning data from Graff.
This switch can help us to find out the difference response between SDP and Graff and report to the monitor system, helping to track the accuracy of our services.
Gray Release
When publishing the service only, the gray release strategy is needed. We deployed one pod at first and watch it. Over a period of time, we check the reports of inconsistent data, service performance,error logs and other metrices. If everything is OK, we publish and deployed the remaining instances.
Conclusion
This is really a big task and a long way to accomplish it. We learn a lot from it. Thanks to the support of our company and team. Hope this article can help you in your work.